En este artículo describimos la arquitectura SMACK y sus componentes y como nos puede ayudar para procesar información mediante Fast Data.
Introducción
En la actualidad, las fuentes de datos disponibles están creciendo de forma vertiginosa, la validez de los datos se vuelve obsoleta más rápidamente y su análisis se vuelve demasiado lento para obtener un retorno de la inversión (ROI) de la información. El desafío es poder analizar la información de una forma adecuada para que el ROI de todos nuestros esfuerzos sea rentable.
Nuevas Necesidades de Procesamiento de información
Es por esto por lo que se hacen necesarias nuevas formas de procesar la información, cuyas necesidades son:
- Infraestructuras escalables: La escalabilidad en un centro de datos significa que el centro debe de crecer en proporción al crecimiento del negocio. La escalabilidad vertical implica agregar más capas de procesamiento. La escalabilidad horizontal significa que una vez que una capa tiene más demanda y requiere más infraestructura, se puede agregar más hardware para que se cumplan las necesidades de procesamiento. Un requisito moderno es tener escalamiento horizontal con hardware de bajo costo.
- Centros de datos geográficamente dispersos: Las empresas necesitan tener múltiples centros de datos en varias ubicaciones por razones de costo, facilidad de administración o acceso a los usuarios. Esto implica un gran desafío para la administración del centro de datos y adicionalmente, la unificación de los mismos es una tarea compleja.
- Permitir que los volúmenes de datos escalen según las necesidades de la empresa: El volumen de datos debe escalar dinámicamente de acuerdo con las demandas del negocio, lo que implica que podremos tener mucha demanda en un momento determinado del día o tener una gran demanda en ciertas regiones geográficas. El escalado debe ser dinámico y posible en el tiempo y espacio, especialmente en sentido horizontal.
- Procesamiento rápido: Trabajar en tiempo real es fundamental donde la frescura de los datos importa más que la cantidad o su tamaño. Si los datos no se procesan lo suficientemente rápido, estamos perdiendo oportunidades y adicionalmente, los datos quedan obsoletos. La nueva información no solo debe obtenerse de forma rápida, sino que debe procesarse rápidamente.
- Procesamiento complejo: Los datos en bruto no nos ayudan mucho, la información debe procesarse en varias capas y de manera eficiente. Las primeras capas suelen ser puramente técnicas y las ultimas orientadas principalmente al negocio.
- Flujo de datos constante: Por razones de costo, los datawarehouses se están volviendo muy caros y sin sentido. La tendencia comercial es hacia flujos de datos realizando el análisis de datos en grandes torrentes de información es uno de los objetivos de las empresas modernas.
- Análisis visible y reproducible: Si no podemos reproducir los fenómenos, no podemos llamarlos científicos. Los datos científicos actualmente requieren de informes y graficos en tiempo real para tomar las mejores decisiones. El objetivo de esto es realizar predicciones basadas en la observación por tanto, el proceso debe ser visible y reproducible.
¿Es esto Big Data?
En muchas de las ponencias que imparto, me realizan esta pregunta. En mi opinión, el termino Big Data confunde y está más enfocado al propio marketing que genera la palabra que al propio concepto. Podriamos hablar de las 3, 4, o 5Vs. De como se crearon nuevas formas de procesado de datos, como Apache Hadoop o Google Big Table, pero no porque los datos fueran grandes (que lo son) o con cantidades enormes (si hiciéramos esta pregunta a profesionales que trabajan con BBDD o Datawarehouses seguramente nos indicaran que ellos ya trabajaban con grandes volúmenes de datos), sino como una nueva forma de procesar la información, más rápida y coherente.
Las Técnologias que van alineadas a este nuevo formato de proceso de información son Cloud Computing , NOSQL o NOETL.
Pero, ¿Que es SMACK realmente?
SMACK es el acrónimo que significa Spark, Mesos, Akka , Cassandra y Kafka. Este acrónimo fue creado por Mesosphere , una compañía que combina estas tecnologías en un producto llamado Infinity, diseñado en colaboración con Cisco para resolver algunos desafíos de pipelines de datos donde la velocidad de respuesta es fundamental, como puede ocurrir en los motores de detección de fraude.
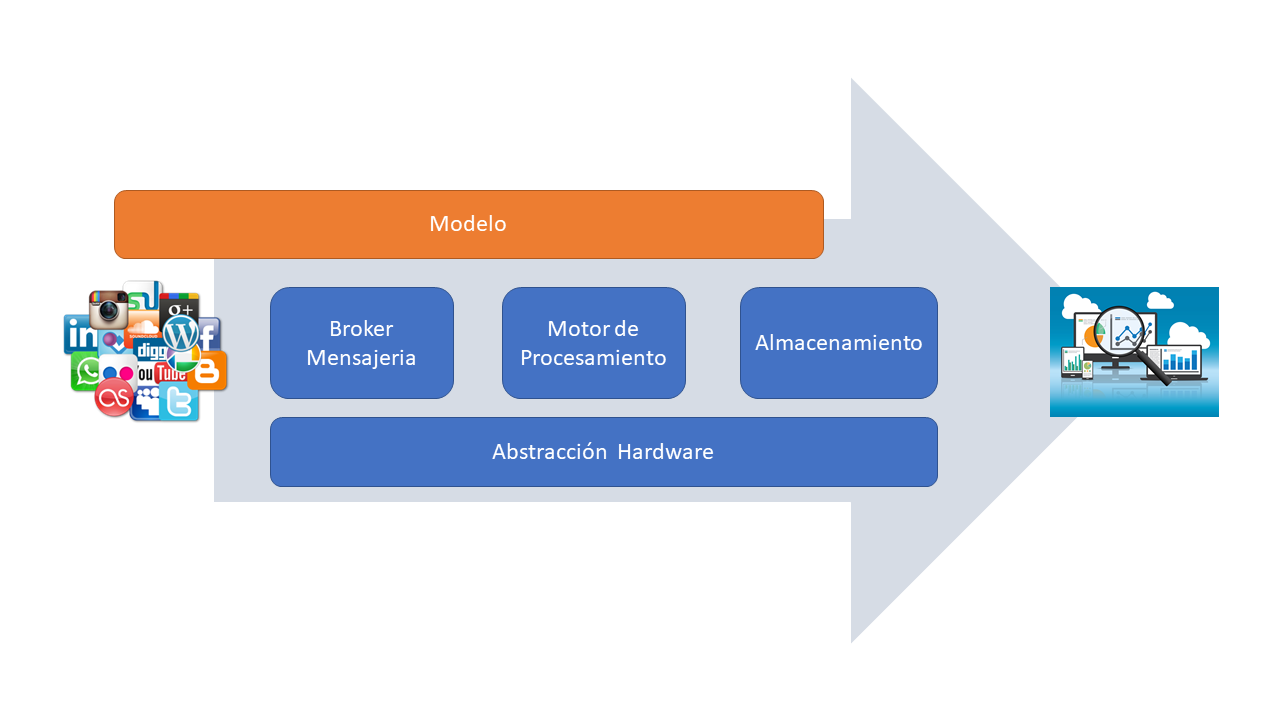
SMACK es un modelo de arquitectura segmentado para el procesamento de datos. Un canal de datos es un software que consolida los datos de múltiples fuentes y lo disponibiliza para ser utilizado estratégicamente.
Lo llamamos pipeline porque cada tecnología contribuye con sus características a la linea de procesamiento. Aunque en nuestra Arquitectura de referencia se combinan las tecnologías que componen este nombre, nos quedaremos con el concepto, en el que podremos utilizar estas u otras técnologias para obtener un mismo resultado. De forma abstracta y en este contexto, nuestra arquitectura de referencia canónica tiene las siguientes capas: Almacenamiento, el broker de mensajeria, Modelo, el motor de procesamiento y la abstracción de hardware.
En posteriores articulos vamos a analizar cada una de las capas y las herramientas que podremos utilizar, comenzando con Mesos .