En este articulo explicamos como se gestiona la alta disponibilidad de maestros de apache mesos y cómo lograr el objetivo utilizando apache zookeeper, lo que nos servirá a futuro para hacer lo mismo con otros servicios como apache kafka.
Introducción
Tras comentar la arquitectura a alto nivel de Apache Mesos, en este primer artículo de la serie Mesos Internals vamos a comentar porque es necesaria la alta disponibilidad y cómo podemos implementarla en Apache Mesos.
Como hemos visto en el artículo anterior, Apache Mesos trabaja en un modo de scheduling de 2 niveles. En el primer nivel, los agentes informan al maestro de los recursos disponibles que tienen. El maestro, por su parte, oferta estos recursos a los frameworks que quieren realizar alguna ejecución.
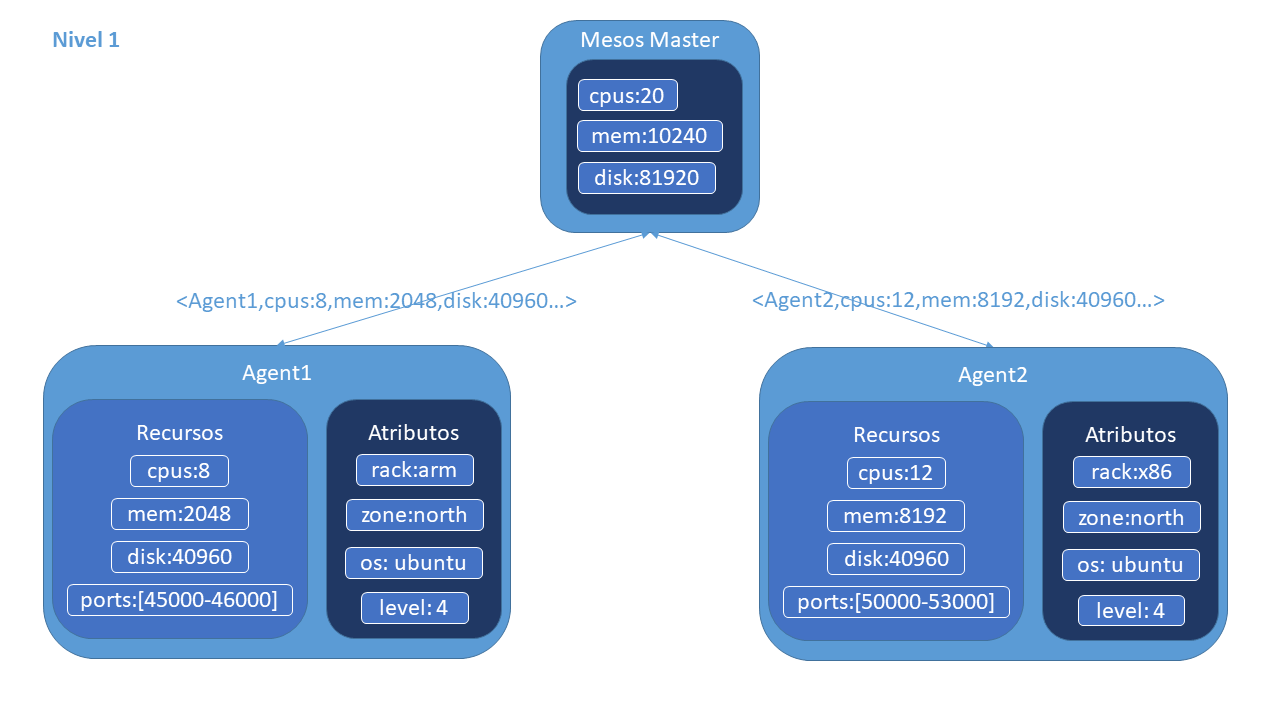
En el segundo nivel, si la oferta es aceptada por algún framework, el scheduler del mismo envía la información sobre las tareas a ejecutar y cantidad de recursos para cada una de ellas. El maestro las traslada a los agentes, que reservan los recursos para poder ejecutar cada tarea solicitada por el framework siendo el framework el encargado de ejecutarlas en el agente.
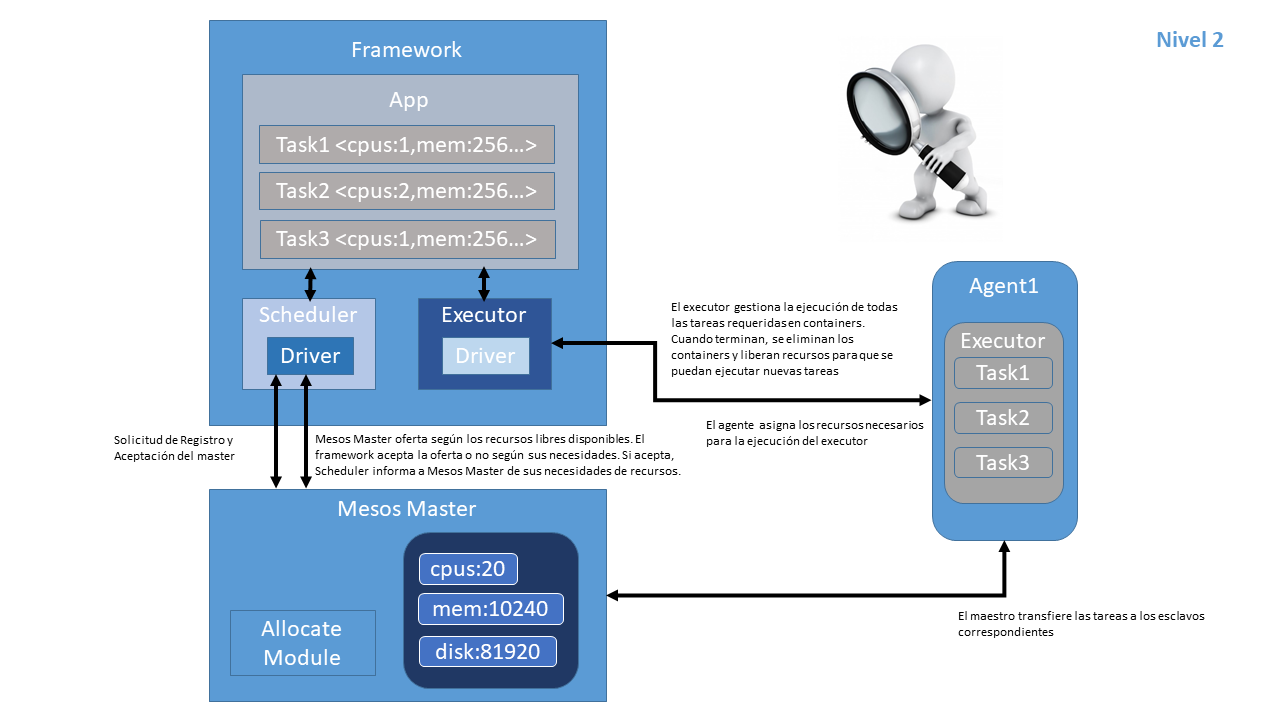
Si nos fijamos en el paso anterior, una vez que el maestro traslada a los agentes las necesidades del framework, “se quita de en medio” y observa, es decir, la ejecución de las tareas sigue su curso y no es necesario el maestro.
Pero ¿qué ocurre si otro framework necesitar realizar la ejecución o el mismo framework quiere realizar nuevas ejecuciones de tareas y el nodo maestro se cae, por cualquier razón?
Aquí es donde entra apache zookeeper en juego y en el corto plazo, también entrará etcd. En este artículo, vamos a explicar en detalle como disponer de alta disponibilidad en los nodos maestros para evitar que suceda lo comentado en esta introducción.
Apache zookeeper
Apache Zookeeper es un servicio de coordinación para aplicaciones distribuidas y es usado por apache mesos para la coordinación entre los nodos maestros y elección del nodo maestro activo.
Instalación
Para instalar apache zookeeper, primero tenemos que instalar la versión de oracle de la jvm. Aunque esto no es necesario, tengo por costumbre realizarlo de esta manera ya que la jvm ofrece mejor rendimiento:
# Instalamos oracle java
$ sudo add-apt-repository ppa:webupd8team/java
$ sudo apt-get update
$ sudo apt-get install oracle-java8-installer
Ahora instalamos zookeeper:
# Instalación de zookeeper en cada nodo
$ sudo apt-get install zookeeperd
Configuración
# Configuración de zookeeper
$ sudo vi /etc/zookeeper/conf/my
# /etc/zookeeper/conf/my
# Cada nodo viene nombrado por un numero unico de identificación [1-255], para cada nodo pondremos [1|2|3]
1
# Configuracion de zookeeper
# copiamos el fichero de ejemplo en otro fichero llamado zoo.cfg
$ sudo vi /etc/zookeeper/conf/zoo.cfg
# /etc/zookeeper/conf/zoo.cfg
server.1=nodo:2888:3888
server.2=nodo:2888:3888
server.3=nodo:2888:3888
# Cambiaremos nodo por la ip del nodo correspondiente de zookeeper o su nombre si usamos dns o tenemos configurado /etc/hosts para responder al mismo
# Este fichero es comun para los 3 nodos de zookeeper
Arranque y parada
Para iniciar apache zookeeper, primero lo activaremos y luego lo iniciaremos:
$ sudo systemctl enable zookeeper.service # Para activarlo
$ sudo systemctl start zookeeper.service # Para arrancarlo
Para parar el el servicio:
$ sudo systemctl stop zookeeper.service # Para pararlo
Elección de nodo lider
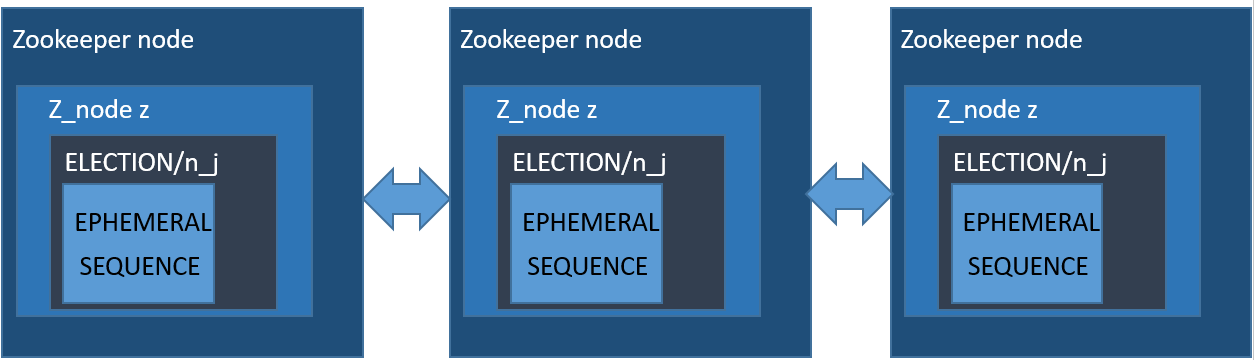
Siendo ELECTION la ruta de elección, para que un nodo sea elegido lider:
- Se crea un nodo znode z con la ruta “ELECTION / n_” con los indicadores SEQUENCE y EPHEMERAL;
- Sean C los hijos de “ELECCIÓN”, y z el numero de secuencia;
- Se observan los cambios en “ELECTION / n_j”, donde j es el número de secuencia más grande, de modo que j <i y n_j es un znode en C;
- Se elige como nodo lider al nodo que tenga un numero de secuencia más pequeño, es decir, n_j
Al recibir una notificación de eliminación de znode:
- Sea C el nuevo conjunto de hijos de ELECTION;
- Si z es el nodo más pequeño en C, entonces se ejecute el procedimiento de líder;
- De lo contrario, se siguen observando los cambios en “ELECCIÓN / n_j”, donde j es el número de secuencia más grande, de modo que j <i y n_j es un znode en C;
Una forma sencilla de hacer una elección de líder con apache zookeeper es usar las banderas SEQUENCE | EPHEMERAL al crear znodes que representan “propuestas” de clientes. La idea es tener un znode, diga “/ election”, de modo que cada znode cree un znode hijo “/ election / n_” con ambas banderas SEQUENCE | EPHEMERAL. Con el indicador de secuencia, ZooKeeper agrega automáticamente un número de secuencia que es mayor que cualquiera que se haya agregado previamente a un elemento secundario de “/ election”. El proceso que creó el znode con el número de secuencia añadido más pequeño es el líder.
Pero es importante estar atento a las fallas del líder, para que surja un nuevo cliente como el nuevo líder en el caso de que el líder actual falle. Una solución trivial es tener todos los procesos de aplicación observando el znode más pequeño actual, y verificar si son los nuevos líderes cuando desaparezca el znode más pequeño (tenga en cuenta que el znode más pequeño desaparecerá si el líder falla porque el nodo es efímero).
Pero esto causa un efecto de manada: ante la falla del líder actual, todos los demás procesos reciben una notificación, y ejecutan getChildren en “/ election” para obtener la lista actual de hijos de “/ election”. Si el número de clientes es grande, provoca un aumento en el número de operaciones que los servidores de apache zookeeper deben procesar. Para evitar el efecto manada, es suficiente observar el siguiente znodo hacia abajo en la secuencia de znodos. Si un cliente recibe una notificación de que el znode que está viendo se ha ido, entonces se convierte en el nuevo líder en el caso de que no haya un znode más pequeño. Hay que tener en cuenta que esto evita el efecto de manada al no tener a todos los clientes mirando el mismo znode. Por ultimo. hay que tener en cuenta que el znode que no tiene un znode precedente en la lista de hijos no implica que el creador de este znode sea consciente de que es el líder actual. Las aplicaciones pueden considerar crear un znode separado para reconocer que el líder ha ejecutado el procedimiento de líder.
Quorum
¿Cuántos apache zookeeper debo correr? Esta el una de las primeras preguntas que nos hacemos al configurar zookeeper por primera vez. Podemos ejecutar un conjunto apache zookeeper que comprende solo 1 nodo, pero en producción se recomienda que ejecute un conjunto apache zookeeper de 3, 5 o 7 máquinas; Cuantos más miembros tenga un conjunto, más tolerante será el conjunto de las fallas del host. Además, ejecutaremos un número impar de máquinas. Aunque depende del servicio que usé apache zookeeper, es una buena práctica que cada servidor ZooKeeper disponga de alrededor de 1 GB de RAM y, si es posible, su propio disco dedicado (Un disco dedicado es lo mejor que puede hacer para garantizar un conjunto de ZooKeeper con rendimiento).
Para que el servicio apache zookeeper, esté activo, debe haber una mayoría de máquinas que no fallan y que puedan comunicarse entre sí. Para crear una implementación que pueda tolerar la falla de las máquinas F, debe contar con la implementación de máquinas 2xF + 1.
Por lo tanto, una implementación que consta de tres máquinas puede manejar una falla, y una implementación de cinco máquinas puede manejar dos fallas. Usamos un numero de máquinas impares porque una implementación de seis máquinas solo puede manejar dos fallas, ya que tres máquinas no son la mayoría. Para lograr la mayor probabilidad de tolerar una falla, deberemos de intentar que las fallas de la máquina sean independientes.
Replicated logs
En el caso de logs, apache mesos tiene “2 sabores”. Uno es mantener los logs en memoria, esto aplica a una máquina de desarrollo, por ejemplo. El segundo sabor se refiere a replicar los logs de cada máquina master haciendo uso de zookeeper.
Un clúster estará operativo siempre que haya un quórum de maestros “recuperados” disponible en el clúster. La cantidad de maestros en el conjunto (cluster) con el que se comunica el maestro actual (incluido él mismo) para formar el quórum de registro replicado. Es imperativo que este número sea siempre menor que --quorum * 2 para prevenir el maestros divididos. También es importante que sea mayor o igual a --quorum para mantener la disponibilidad.
Conclusiones
Hemos explicado el funcionamiento de zookeeper, la configuración, arranque y parada de este servicio. El número de nodos de zookeeper siempre debe de ser una cantidad impar ya que no obtenemos beneficio aplicando una cantidad par con respecto de las fallas de las que queremos protegernos. Por ultimo, tambien hemos visto que para que dispongamos de un lider, es necesario un quorum, un consenso al que se llega entre los nodos de zookeeper y que debe de ser 2xF + 1.
Teniendo este artículo como base, en el siguiente artículo utilizaremos zookeeper junto a apache mesos para dotarle de alta disponibilidad para los maestros y replicar los logs entre ellos.